文章目录
- 题目
- 摘要
- 方法
- 实验
题目
检索增强大语言模型的查询重写

论文地址:https://arxiv.org/abs/2305.14283
项目地址:https://github.com/xbmxb/RAG-query-rewriting
摘要
大语言模型(LLM)在检索--然后阅读(retrieve--then--read)管道中发挥着强大的黑盒阅读器的作用,在知识密集型任务中取得了显著进展。这项工作从查询重写的角度出发,为检索增强型 LLMs 引入了一个新的框架,即重写-检索-阅读(Rewrite-Retrieve-Read),而不是以前的检索-重写-阅读(Retrieve-then-read)。与之前侧重于调整检索器或阅读器的研究不同,我们的方法关注的是搜索查询本身的调整,因为输入文本与检索所需的知识之间不可避免地存在差距。我们首先促使 LLM 生成查询,然后使用网络搜索引擎检索上下文。此外,为了更好地将查询与冻结模块相匹配,我们为我们的管道提出了一个可训练的方案。我们采用一个小型语言模型作为可训练的重写器,以满足黑盒 LLM 阅读器的需要。通过强化学习,利用 LLM 阅读器的反馈对改写器进行训练。在下游任务、开放域质量保证和多选质量保证上进行了评估。实验结果表明性能得到了持续改善,这表明我们的框架被证明是有效的、可扩展的,并为检索增强型 LLM 带来了新的框架。
方法
我们提出了 “重写-检索-阅读”(Rewrite-Retrieve-Read),这是一个从查询重写角度改进检索增强 LLM 的管道。下图显示了一个概览。
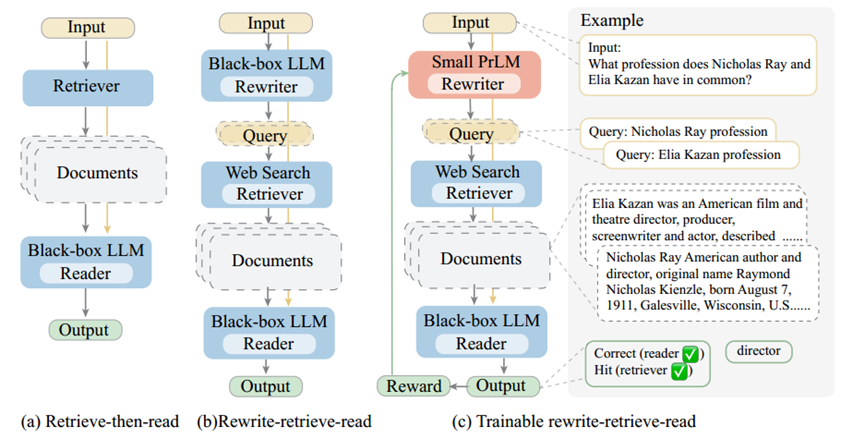
带有检索增强的任务可表示如下。给定一个知识密集型任务的数据集(如开放域 QA),D = {(x, y)i}, i = 0, 1, 2, . , N,x(如问题)是管道的输入,y 是预期输出(如正确答案)。我们的管道包括三个步骤。(i) 查询重写:根据原始输入 x 生成所需知识的查询 x˜;(ii) 检索:搜索相关上下文 doc;(iii) 阅读:理解输入和上下文 [doc, x],并预测输出 yˆ。一种直接而有效的方法是要求 LLM 重写查询,以搜索可能需要的信息。我们使用一个短促的提示来鼓励 LLM 思考,输出可以是没有、一个或多个搜索查询。
此外,完全依赖冻结的 LLM 也有一些缺点。推理错误或无效搜索会影响性能。另一方面,检索到的知识有时会误导和损害语言模型。为了更好地与冻结模块保持一致,可以添加一个可训练模型,并通过将 LLM 读者的反馈作为奖励来调整该模型。基于我们的框架,我们进一步建议利用一个可训练的小语言模型来接管改写步骤,如上图右侧所示。可训练模型由预先训练好的 T5-large (770M) 初始化,称为可训练改写器 Gθ。重写器首先在伪数据上进行预热训练,然后通过强化学习进行持续训练。
查询重写任务与T5等序列到序列生成模型的预训练目标有很大不同。首先,我们为查询重写任务构建一个伪数据集。受最近的蒸馏方法的启发,我们提示LLM重写训练集中的原始问题x,并收集生成的查询x~作为伪标签。然后对收集到的样本进行过滤:那些从 LLM 阅读器获得正确预测的样本被选入预热数据集,表示为 DTrain = {(x, x~)|yˆ = y}。重写器 Gθ 在 DTrain 上进行微调,以标准对数似然作为训练目标,表示为
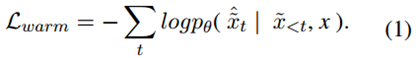
预热后的重写器模型表现出适度的性能,这取决于伪数据质量和重写器能力。由于高度依赖于人工编写的提示行,x~ 可能不是最优的。重写器尺寸相对较小也是预热后性能的限制。然后我们转向强化学习,使重写器与下面的检索器和法学硕士读者保持一致。
为了进一步微调重写器以迎合LLM读者,我们采用了策略梯度强化学习框架。任务制定 在强化学习的背景下,重写器优化被制定为马尔可夫决策过程 5 元组⟨S、A、P、R、γ⟩。
- 状态空间 S 是受词汇和序列长度限制的有限集。
- 动作空间 A 等于词汇表。
- 转移概率 P 由策略网络决定,即重写器模型 Gθ。
- 奖励函数 R 给出取决于当前状态的奖励值。策略梯度源自奖励,用作训练目标。 (v) γ 表示折扣因子。
更具体地说,预热后的重写器 Gθ 是初始策略模型 π0。在每个步骤 t,at 的动作是根据当前状态的观察生成下一个标记 ˆ~xt,st = [x, xˆ~<t]。当生成被句子结束标记停止时,一集就结束了。完成检索和阅读后,通过评估最终输出来计算奖励,即 LLM 读者预测的分数。策略优化我们采用近端策略优化。奖励 R 的期望最大化表述为
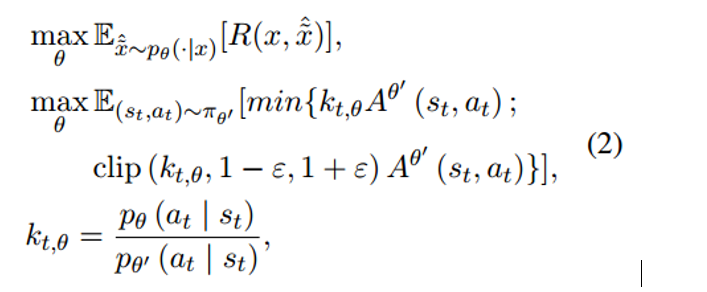
其中 θ ′ 是临时固定的采样策略,并且 θ 被更新。 A表示优势函数,它是基于价值网络Vψ的估计而制定的。价值网络 Vψ 由策略网络 π0 初始化。该公式遵循广义优势估计 (GAE),其中 λ 是偏差-方差权衡参数。
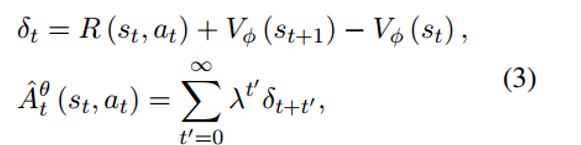
奖励函数R反映了生成的查询的质量,需要与任务的最终评估保持一致。 x^ 被馈送到检索器和读取器以得到最终预测 y^。奖励函数的一部分是 y^ 与黄金标签 y 相比的度量(例如,预测答案的精确匹配和 F1),表示为 Rlm。此外,还添加了 KL 散度正则化,以防止模型偏离初始化太远。最终的损失函数由策略损失和价值损失组成。这里,S表示采样集,T表示步数。
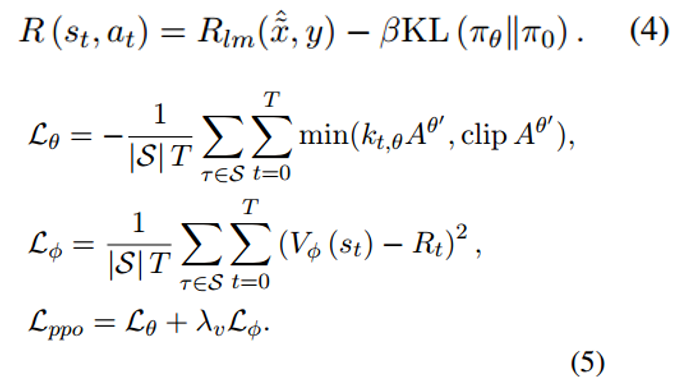
实验
对于冻结管道,我们提示法学硕士通过少量上下文学习重写查询。我们的提示遵循[指令、演示、输入]的表述,其中输入是x。说明很简单,演示是训练集中的 1-3 个随机示例,并且在所有运行中保持不变,主要用于特定于任务的输出格式说明,即,一个简短的短语作为 HotpotQA 的答案,以及一个选项作为答案对于MMLU。对于训练方案,我们微调T5作为重写器。
我们使用 Bing 搜索引擎作为检索器。它不需要像密集检索器那样构建候选索引,也不需要像教科书那样构建候选索引。但它允许广泛的知识范围和最新的事实性。使用 Bing API,可以通过两种方法执行检索。 (i) 对于所有检索到的网页,我们将 Bing 选择的相关句子的片段连接起来。这种方法类似于在浏览器中使用搜索引擎,输入查询并按回车键,然后收集搜索结果页面上显示的文本。 (ii) 对于检索到的网页,我们请求 URL 和解析器来获取所有文本。这类似于单击搜索结果页面上的项目。然后我们使用 BM25 保留那些具有较高相关性分数的查询,从而减少文档长度。
阅读器是一个冻结的 LLM,我们采用了 ChatGPT(gpt-3.5-turbo)和 Vicuna-13B。它通过少量的上下文学习来进行阅读理解和预测。在我们的提示中,在简短的指导和示范之后,输入是 x 或带有检索增强的 [doc, xˆ˜]。事实证明,提示语的措辞和示范的选择都会影响情境学习的效果。由于这不是本研究的重点,我们不再关注提示语的编辑。
保证评估使用了三个开放域 QA 数据集。(i) HotPotQA(由需要多跳推理的复杂问题组成。我们对全部测试集进行了评估。(ii) AmbigNQ提供了自然问题(NQ)的消歧版本。对于 NQ 中模棱两可的问题,会添加最小的限制条件,将其分解为几个相似但具体的问题。前 1000 个样本在测试集中进行评估。(iii) PopQA包含长尾分布,因为它比其他流行的质量保证任务包含更多低流行度知识。我们将该数据集分为 13k 个训练集和 714 个测试集。
开放域质量保证基准是问题-答案对的集合,表示为 {(q,a)i}。我们将 ChatGPT 用于阅读器和冷冻改写器。评估指标是精确匹配(EM)和 F1 分数。对于 RL 中的奖励函数,我们使用一个指标,如果检索内容命中答案,则给予奖励;如果未命中答案,则给予惩罚,记为 Hit。总奖励是 EM、F1 和 Hit 的加权和。
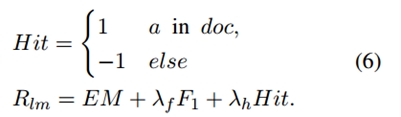

对于多选题质量保证,我们在大规模多任务语言理解(MMLU)(Hendrycks 等人,2021 年)上进行了评估: 该试题数据集包括 4 个类别:人文科学、STEM、社会科学和其他。每个类别分为 80% 的训练集和 20% 的测试集。多选 QA 可表述为 {(q ′ , a)i}, 其中 q ′ = [q, c0, c1, c2, c3]。官方提供的污染清单中包含的检索文件将被忽略。带有选项的问题会被改写成搜索查询。答案就是一个选项。EM 被报告为指标并用于奖励。我们使用 ChatGPT 作为冻结重写器和读取器。由于 ChatGPT 的速率限制问题,我们还使用 Vicuna-13B 作为读取器进行评估。
为了评估和支持我们的方法,我们采用了以下设置。(i) 直接:标准的上下文学习,无任何增强。(ii) 检索-阅读: 标准的检索增强方法。检索到的文档与问题连接在一起。(iii) 作为冻结重写器的 LLM: 我们促使一个冻结的 LLM 通过少量的上下文学习来推理和生成查询。(iv) 可训练的重写器: 应用微调后的重写器,输出查询供检索器和阅读器使用。下表列出了提示行的形式。请注意,每个任务的预测提示都是相同的。
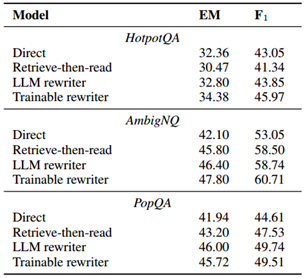
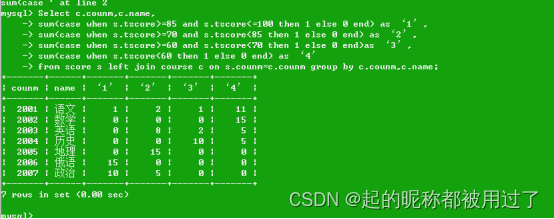
在这三个数据集上,使用冻结重写器和可训练重写器,查询重写始终能带来性能提升。在 AmbigNQ 和 PopQA 中,标准检索增强了阅读器,表明有用的外部知识被检索到了。在 HotpotQA 中,标准检索损害了读者。这表明,使用复杂问题作为查询无法弥补参数知识,反而会带来噪音。这表明多跳问题不适合网络搜索引擎查询。通过增加改写步骤,分数会提高。在 PopQA 上,我们的可训练改写器超过了标准检索,但不如 LLM 改写器。这表明,查询改写的提炼效果并不理想。
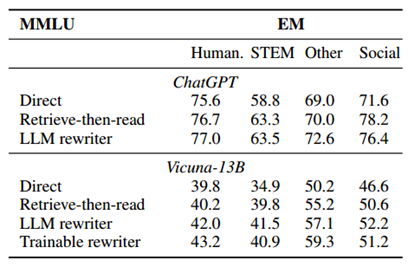
使用 ChatGPT 作为阅读器时,可以发现查询重写提高了除社会科学类别之外的大多数类别的分数。与 ChatGPT 相比,使用 Vicuna 作为阅读器时,我们的方法在四个类别中都取得了更高的分数。这与我们的直觉相吻合,即更强大的阅读器拥有更多的参数记忆,因此更难以用外部知识来弥补。
训练过程包括热身和强化学习两个阶段。本节展示了三个开放域质量保证数据集的验证得分,以供进一步分析。下图显示了在强化学习过程中通过训练迭代得到的度量分数。由于改写模型在 RL 之前已经在伪数据上进行了热身,因此 "0 次迭代 "时的分数表示从热身训练中获得的能力。
可以看出,在所有数据集上,曲线都呈上升趋势,但也有一些波动。(i) 对于 HotpotQA 中的多跳问题,标准检索相对较弱。复杂问题可能不是特定的搜索查询,与重写查询的差距较大,即绿线和红线。(ii) 在 AmbigNQ 和 PopQA 上,我们的方法在多次迭代(3 或 4 次)后超过了基线。这表明在热身训练阶段,RL 训练阶段可以弥补伪数据蒸馏的不足。(iii) 特别是在 PopQA 上,可训练重写器仍然不如 LLM 重写器。这可以解释为该数据集是为自适应检索而构建的,自适应检索只使用有助于避免有害冗余检索的检索。因此,"无 "是一个可能的查询,意味着没有检索。这会导致更多的复杂性和不确定性。LLM 重写器更清楚自己作为阅读器何时需要检索,尽管重写步骤并不作为阅读器的输入上下文。
我们计算查询 "无 "的性能。无需检索即可正确回答的问题(即 "直接 "方法)是那些不需要更多上下文的样本。将这些无需检索的问题集与改写为 "无 "查询的问题集进行比较,LLM 改写器的 F1 得分为 71.9%,T5 改写器的得分为 67.1%。如果我们将无需检索即可正确回答、但检索后出错的问题视为无检索集,那么 LLM 重写器的 F1 得分为 78.7%,T5 重写器的 F1 得分为 77.4%。
我们提出的方法是一个管道框架,而不是端到端系统。查询重写首先影响检索上下文,然后上下文对阅读器的输出产生影响。因此,质量保证指标是间接测量。我们通过检索指标 "命中率 "来仔细观察检索上下文和阅读器的能力。文本规范化后,命中率将被计算出来,以衡量检索到的上下文是否包含正确答案。
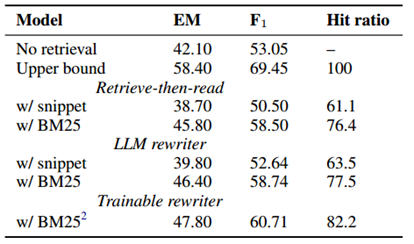
下表显示了 AmbigNQ 的得分。第二行中的分数是根据检索语境命中正确答案的部分样本计算得出的(在标准检索-然后阅读设置下)。这些分数显示了阅读器在检索增强后的近似上限能力,简称为 "上限 "分数。与无检索设置(第一行)相比,检索的有效性得到了证明。每种检索方法都有两种设置:(i) 收集必应片段,(ii) 通过 BM25 从 URL 中进行选择。度量指标显示,使用 BM25 进行内容选择比片段检索能检索出更好的文档,而查询重写在两种设置下都取得了进步。我们还观察到,检索器命中率的提高比阅读器的提高更显著。这与相关搜索的研究结果一致。
为了直观地展示查询重写如何对检索到的上下文和预测性能产生影响,我们在下图中举例比较了原始问题和查询。在示例 1 中,原始问题询问玛丽-盖伊-寇松夫人的小女儿与某两位演员共同主演的一部电影。查询 1 和查询 2 都将关键字 "电影 "放在前面,紧跟着玛丽-盖伊-寇松夫人的小女儿。通过这两个查询,可以检索到女演员夏洛特-卡尔索普及其电影信息,并包含答案。第二个例子是来自 LLM 重写器的查询失败,但来自 T5 的查询却得到了正确答案。在查询 1 中,数字 2000 被误解,而查询 2 则将 200 部电影放在一起,避免了无意义的检索。例 3 是多选题。该查询简化了背景,增强了关键词社区规划器。检索背景主要是关于社区规划简介,其中答案环境出现了多次。